Normally, we are given a table, which looks like this.
Every column in this table indicates how observable data is distributed under given hypothesis. The probabilities, conditional on hypothesis, in the column must sum to 1. By multiplying the column entries with hypothesis priors below the columns, we arrive at joint distribution
Finally, dividing the row entries with data marginal probabilities Dn probabilities, we arrive at the Bayesian table
It displays how hypothesis are distributed given observable data (a row). Note that rows always sum to 1.
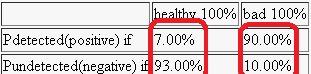
 Summing along the rows, we get the distribution of matter between the rows. We could also sum the columns but we already know the result -- these are prior distributions of our hypothesis. If we now divide every individual box by the row total weight (the data probability) now, we'll get the desired probability of hypothesis given the evidence (data)
Summing along the rows, we get the distribution of matter between the rows. We could also sum the columns but we already know the result -- these are prior distributions of our hypothesis. If we now divide every individual box by the row total weight (the data probability) now, we'll get the desired probability of hypothesis given the evidence (data)
It is convenient to do with my automatic table transform.
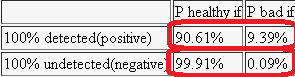
It is curious to note the Posterior Odds, Ω₁ = 9.39/90.61 = 0.103630946. Video above says that it can be computed simpler, by Baes's rule: P(H₁|D)/P(H₂|D) = Ω₁ = Ω₀ · LR = P(H₁)/P(H₂) · P(D|H₁) / P(D|H₂).
For this reason, we could bypass the joint probability, which was necessary just to compute P(Detected):
Ω₁ = .8/99.2 · 90/7 = 0.103686636. First I have seen that common denominator is avoided as long as possible in the Allen Downy tutorial.He also convinced us that the relative confidence, the ratio between theory probabilities (aka odds), is only important whereas absolute probability is not.
It had to be true because
P(H₁|D) P(D) = P(D|H₁) P(H₁)
P(H₂|D) P(D) = P(D|H₂) P(H₂)
and dividing one by the other, we get
P(H₁|D)/P(H₂|D) = P(H₁)/P(H₂) · P(D|H₁) / P(D|H₂) = Ω₀ · LR.
But, that is the same as ratio of joint probs, P(DH₁) / P(DH₂).
It is curious to note that Shane Killan says that probabilities of 0 and 1 are forbidden whereas Allen Doney permits them.
It turns out that Confidence Intervals method operates on the basis of first table: we traverse all hypothesis (or parameters $\theta$) and strip those which have observation D beyond CI. The bayesian method needs the table conversion into T3 to look at the correponding row D and select highest prob hypothesis up to Credibility 95%, throwing the rest out as incredible. It also gives some terminology: $ \underbrace{P(\theta|D)}_\text{posterior} \propto \underbrace{P(D|\theta)}_\text{likelihood} \times \underbrace{P(\theta)}_\text{prior} $
WP: Bayesian inference derives the posterior probabilityas a consequence of two antecedents, a prior probability and a "likelihood function". The priors is initial distribution of the columns, which, upon observation is replaced (or updated) by posteriors -- conditional distribution of probabilities in the observed row from table 3.
| Data | P(D|Hyp1) | P(D|Hyp2) | … |
|---|---|---|---|
| D1 | P(D1|H1) | P(D1|H2) | … |
| D2 | P(D2|H1) | P(D2|H2) | … |
| D3 | P(D3|H1) | P(D3|H2) | … |
| ⋮ | ⋮ | ⋮ | ⋮ |
| Prior(H1) | Prior(H2) | … | |
Every column in this table indicates how observable data is distributed under given hypothesis. The probabilities, conditional on hypothesis, in the column must sum to 1. By multiplying the column entries with hypothesis priors below the columns, we arrive at joint distribution
| Data | P(D,Hyp1) | P(D,Hyp2) | … | |
|---|---|---|---|---|
| D1 | P(D1,H1) | P(D1,H2) | … | ∑:P(D1) |
| D2 | P(D2,H1) | P(D2,H2) | … | ∑:P(D2) |
| D3 | P(D3,H1) | P(D3,H2) | … | ∑:P(D3) |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ∑:Prior(H1) | ∑:Prior(H2) | … | ||
Finally, dividing the row entries with data marginal probabilities Dn probabilities, we arrive at the Bayesian table
| Data | Hyp1 | Hyp2 | … | |
|---|---|---|---|---|
| P(H|D1) | P(H1|D1) | P(H2|D1) | … | ∑:P(D1) |
| P(H|D2) | P(H1|D2) | P(H2|D2) | … | ∑:P(D2) |
| P(H|D3) | P(H1|D3) | P(H2|D3) | … | ∑:P(D3) |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
It displays how hypothesis are distributed given observable data (a row). Note that rows always sum to 1.
This is because there is a classical Bayes problem (also seen in the Tom Carter's book). We are exposed to a distribution of columns
Every column represents a hypothesis and detection is the data distribution over these two, healthy and bad, hypothesises. The problem is to rotate the table by 90 degrees in order to show the distribution over rows, how our hypothesis are distributed given test results. We first build the Joint Distribution
It is convenient to do with my automatic table transform.
It is curious to note the Posterior Odds, Ω₁ = 9.39/90.61 = 0.103630946. Video above says that it can be computed simpler, by Baes's rule: P(H₁|D)/P(H₂|D) = Ω₁ = Ω₀ · LR = P(H₁)/P(H₂) · P(D|H₁) / P(D|H₂).
For this reason, we could bypass the joint probability, which was necessary just to compute P(Detected):
Ω₁ = .8/99.2 · 90/7 = 0.103686636. First I have seen that common denominator is avoided as long as possible in the Allen Downy tutorial.He also convinced us that the relative confidence, the ratio between theory probabilities (aka odds), is only important whereas absolute probability is not.
It had to be true because
P(H₁|D) P(D) = P(D|H₁) P(H₁)
P(H₂|D) P(D) = P(D|H₂) P(H₂)
and dividing one by the other, we get
P(H₁|D)/P(H₂|D) = P(H₁)/P(H₂) · P(D|H₁) / P(D|H₂) = Ω₀ · LR.
But, that is the same as ratio of joint probs, P(DH₁) / P(DH₂).
It is curious to note that Shane Killan says that probabilities of 0 and 1 are forbidden whereas Allen Doney permits them.
It turns out that Confidence Intervals method operates on the basis of first table: we traverse all hypothesis (or parameters $\theta$) and strip those which have observation D beyond CI. The bayesian method needs the table conversion into T3 to look at the correponding row D and select highest prob hypothesis up to Credibility 95%, throwing the rest out as incredible. It also gives some terminology: $ \underbrace{P(\theta|D)}_\text{posterior} \propto \underbrace{P(D|\theta)}_\text{likelihood} \times \underbrace{P(\theta)}_\text{prior} $
WP: Bayesian inference derives the posterior probabilityas a consequence of two antecedents, a prior probability and a "likelihood function". The priors is initial distribution of the columns, which, upon observation is replaced (or updated) by posteriors -- conditional distribution of probabilities in the observed row from table 3.
I have realized that maxization of likelihood f(x1, xn, ... xn, | θ) has a column for every θ that we want to find and x1, xn, ... xn are observations. This means that we have |x|^n rows, where |x| stands for the amount of values that X may take. After sampled n xes we go to the corresponding row and find a column with highest probability. That gives us most likely θ, our estimation of the model parameter.
The tables work that user edits a table until errors are eliminated and results are propagated to the two other tables. It however seems impossible to solve Example 1.12 from Ross: Consider two urns. The first contains two white and seven black balls, and the second contains five white and six black balls. We flip a fair coin and then draw a ball from the first urn or the second urn depending on whether the outcome was heads or tails. What is the conditional probability that the outcome of the toss was heads given that a white ball was selected? because urns are the columns in the first tables whereas distribution [1/2, 1/2] is given for the rows in the third. We need to extend the tables to solve constraint problem.
No comments:
Post a Comment